基于MIT 6.824 2021Spring 课程笔记
MapReduce
算法流程
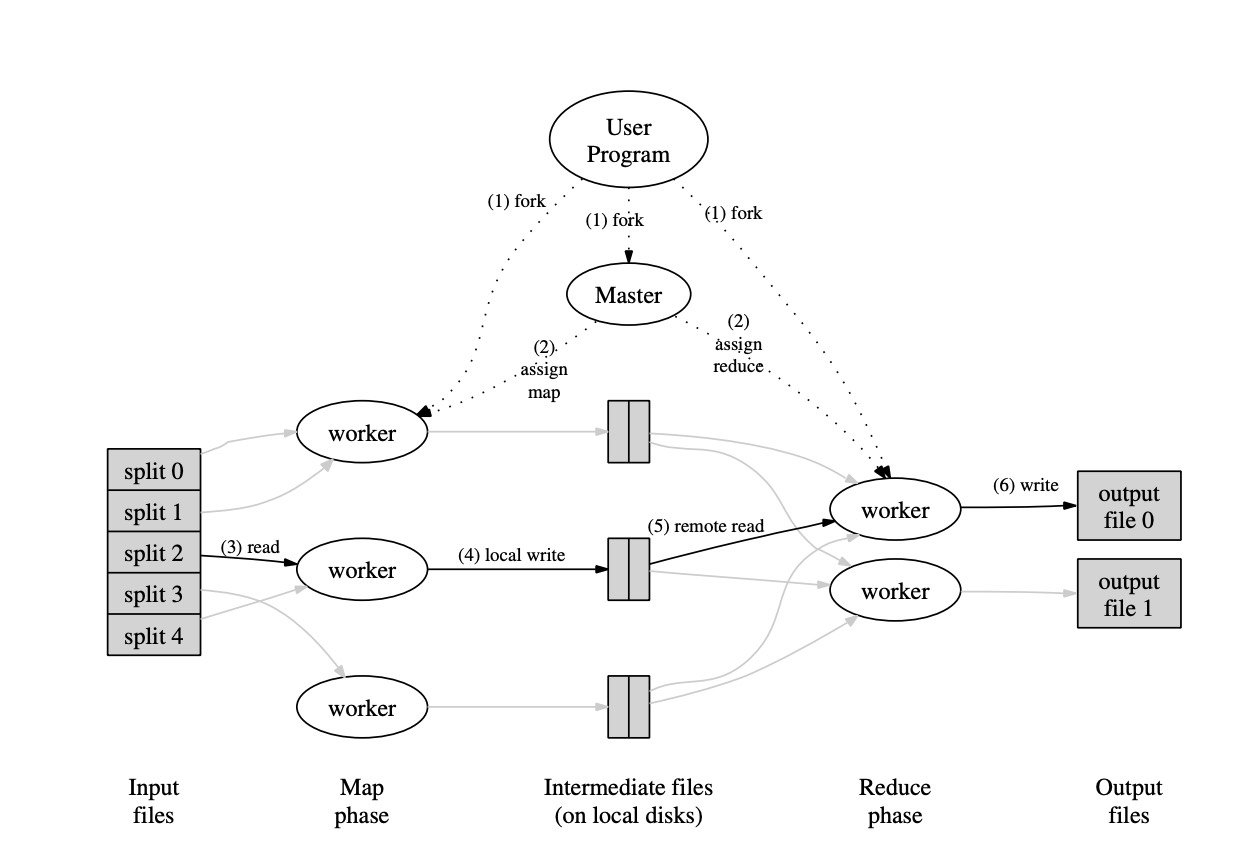
MapReduce的算法流程如下:
- map函数将文件分成M个文件,通常是16-64MB然后储存到文件。
- 多台机器上会有map程序的拷贝在同时运行。其中一台为Master,负责将输入分配到不同的机器上运行。
- 每台Map机器会产生许多个{key, value}对。这些对会使用一个hash函数将key映射到大小为R的空间上,并存储到本机相应位置。这些文件的地址会被传回master。
- Master根据一定的映射关系,将这些地址传给worker。
- 根据Master 的地址,reduce worker会读取这些文件。当文件被完全读取时,reduce worker会首先根据key进行排序,保证相同key的pair会放在一起(这步非常重要,很多例子给的是一个key对一个ruduce worker。但实际上根本没有这么多机器,所以hash是必须的。但是hash又导致了不同的key挤在了同一个worker上的问题,所以需要排序)然后再进行用户定义的Reduce操作。最后得到的结果会输出到R个文件。
算法应用
常见的如统计字符个数,URL计数。当然,最为经典的就是在搜索引擎的反向索引上的应用。对于一个网页,我们定义它的索引为{document, {keywords}}。那么它的反向索引就是{keyword, {documents}}通过这种方式我们就能根据关键字找到可能相关的文件。
容错机制
Worker失效
Master会使用类似心跳包的机制检测worker是否存活。如果发现failure则会将当前worker的任务记为idle,这样其他空余的worker就能够重新开始这个worker的工作。
如果Map机器A fail,那么我们需要重新进行一遍map。原因是map后的结果保存在了worker的本地文件中。同时,如果一台新机器B重新对同一份数据重新跑map,那么会有一个全局的通知让所有还没读取A(因为两份结果都是正确的,所以读完的可以继续跑,但是没读完的没法再读A了,所以转到B)的Reduce机器转而读取B的数据。如果worker fail了那么它的文件我们显然是读取不到的。
如果Reduce机器fail了那么就不需要重新跑。因为Reduce的结果是保存在gfs而不是worker的local file中。
Master失效
一种方法是对master设立checkpoint,这样master fail我们也能从checkpoint重新开始。但是对于单点master,只能让client自己检查是否正确运行。
带宽管理
由于带宽很宝贵,所以MapReduce的一个原则是尽可能在保存数据的机器上执行map操作。Map的worker既能执行map操作,同时它的文件也被gfs管理。在不同的worker上,保存了不同的input的副本。当我们对某个输入A进行map操作时,map会尽可能选择拥有目标输入A的woker进行map。如果所有满足要求的worker都不能进行map操作,那么会选择在同一个网络(机房)的机器进行数据传输以最大可能节约带宽。
备份任务
有的时候,部分机器会在执行任务时运行得异常地慢。比如部分机器的磁盘出现故障,导致其读写速度从30mb/s下降到1mb/s。不同的机器可能有不同的问题,而对停下机器去检查原因是不能接受的。所以mapreduce的论文中提到,他们在任务快要完成时,会同时在另外一台机器上启动backup任务。这个任务是与即将完成的任务完全相同的。当两个任务的其中一个完成时,另一个没有完成的任务将被终止。
跳过损坏记录
有时候由于用户代码的问题,mapreduce会无法完成。通常的操作是找到这个bug并修复。但是有的时候错误如果发生在第三方库,那么就很难修复这个bug。同时,我们在部分场景下,可以接受忽略一些记录,比如在大数据集下的数据统计。Mapreduce提供了一个方法使得用户能够在运行中,判断哪些数据需要丢弃。在MapReduce的worker中有一个handler,会catch段错误和总线错误。出现了这种错误后,worker会发一个udp包到master。如果master发现一个记录有多次错误,那么就会判断要抛弃这个record。