思路
题意是计算字符串所有本质不同的子串。主要思路是利用后缀数组的性质。因为是第一次使用后缀数组,所以在这里稍微做一些笔记。
后缀数组
后缀指的是从字符串的某个位置到字符串结尾的子串(包括原串和空串)。而后缀数组指的是包括所有字符串后缀的一个数组,同时其中的后缀已经完成了字典序的排序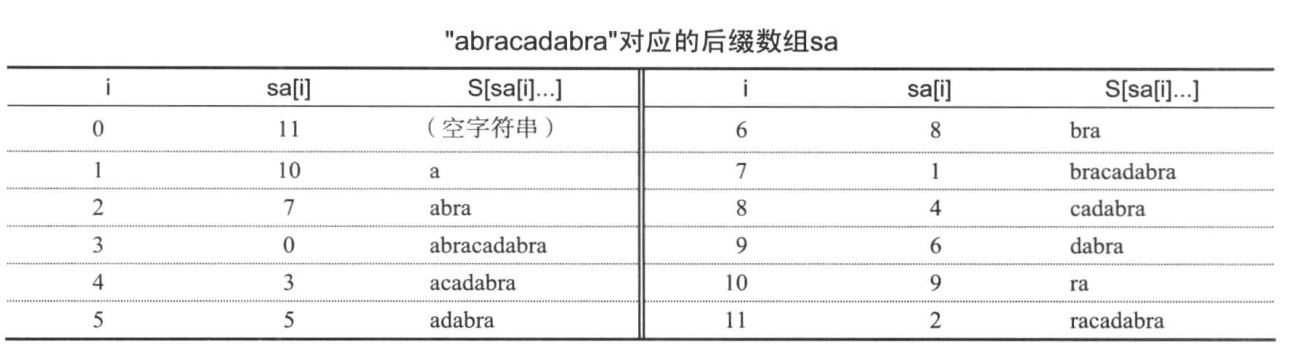
上图就是白书中后缀数组的样例,其中sa[i]指的是从第几个字符开始的后缀。
后缀数组的生成
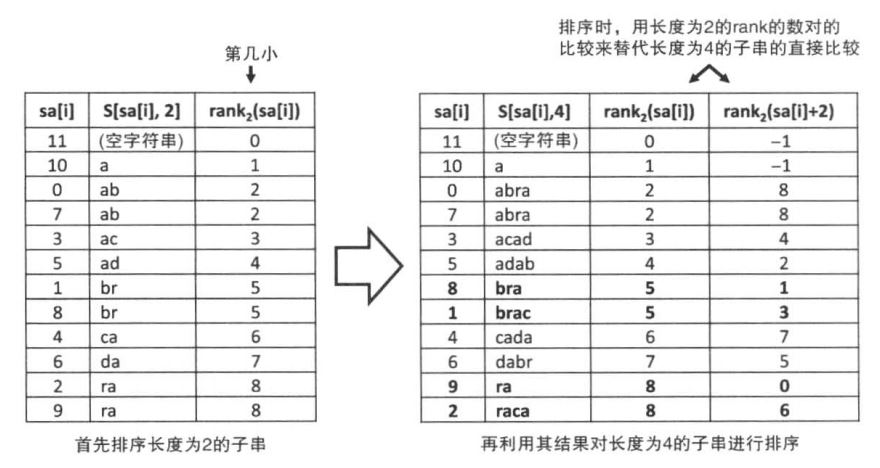
在了解了后缀数组的内容后我们首先来讲讲如何实现。后缀数组的实现类似于基数排序,先比较各个后缀的第一个字符,然后利用这次的比较结果,我们能够计算长度为2的rank(先比较前一个长度为一的字符串,在比较后一个)。通过不断倍增长度最后完成对所有长度字符串的排序,如果发现后半部分长度超过字符串长度的话,就令他为最小的(-1),可以参考下面第二张图的a的第二个rank。这里或许会不能理解为什么可以这样比,难道不会有遗漏的字符使得这样的比较不能够进行吗?答案是否定的。实际上每一个后缀的第一个字符拼在一起就是整个字符串,所以不用担心有缺漏的情况。这个过程的时间复杂度为O(nlog^2n)。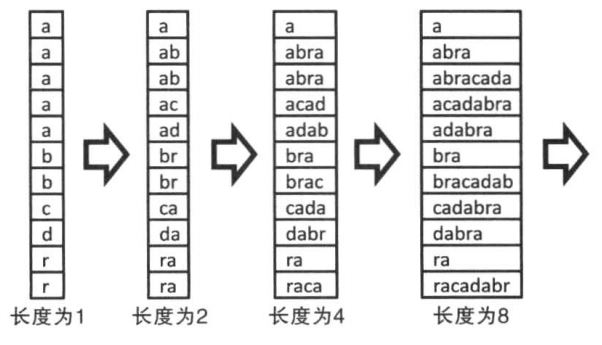
高度数组
高度数组指的是相邻两个后缀的公共最长前缀。
在高度数组中,最关键的就是height[i] ≥ height[i - 1] - 1这个性质。i与i-1指的是sa中相邻的两个后缀,比如abra和bra,从上图中我们能够看到abra后面三个子串和bra后面三个子串只是差一个前面的a,那么我们就能复用之前abra的height数组,所以显然有height[i] ≥ height[i - 1] - 1,构造的时间复杂度为O(n)。
本题思路
在了解了后缀数组的性质后,我们可以发现,一个后缀对子串数量的贡献是str.length()-sa[i]-height[i]。原理是height就是重复的子串,减掉就是去重的过程。
代码
1 |
|